Introduction There are many tutorials on the web to get one started using D3. Links to some of these works will follow later in this article. While they are all wonderful (and I thank each author for getting me over the steep D3 learning curve), most of these...
Customer satisfaction is increasingly being linked to revenue growth for field services companies, with a recent Aberdeen report finding that organizations that achieved a 90% rating in customer satisfaction also enjoyed a 6.1% growth in their service revenues and a...
As python programmers we are sometimes faced with using an API that is, well, unpythonic. Unpythonic? Pythonic? Huh? Have you ever tried running this: python -m this Maybe you’re using a C library via ctypes, or you have inherited a collection of functions....
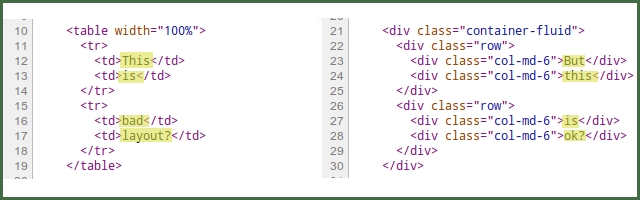
The above diagram shows two ways to place a grid on an HTML page. The <TABLE> version on the left is the old school way of managing layout. The web was positively littered with such code before widespread use of CSS (and browser manufacturer adoption of...
Alright, maybe your grandmother doesn’t need tips for using ssh. In fact, she probably doesn’t even know ssh is a secure shell for accessing a remote host. Go figure. But I know when I reach the age of grandparenthood and I begin contemplating shuffling...