Art+Logic has kicked-off its first software Incubator project, and I was selected to handle the development effort. After meeting Dr. Scott Hawley and being briefed on the technique he uses for classification of audio files using neural networks (NN), and determining current and future features, we were ready to begin the project. While we go through this process, I’ll be documenting it on this blog.

Spectrogram of a Gong
Review
Dr. Hawley’s idea is to use a convolutional neural network (CNN) to classify audio files. And rather than simply forcing users to use the most obvious ways to describe a sound, they can train the CNN with their own ideas on how to organize the sounds.
The app then can organize the user’s sound library based on these custom categories. It will also let the user retrieve any sounds matching one or more of these categories.
Goals
We decided that the initial scope should be kept small, smaller than what Dr. Hawley has already achieved in his own efforts. His technique for categorizing audio files could be applied to many different problems. Consulting with Dr. Hawley, we decided on only sorting audio into a few predetermined categories related to music and leaving the user-controlled training of neural networks for arbitrary categories until later.
This, of course, allows us to get something into users hands as soon as possible and find out whether we are delivering the right solution. At the same time, the minimal feature set makes sure we can begin our quality assurance as soon as possible. Most of all, by putting off network training, we can get by with running our network on the local CPU and not worrying about dealing with GPUs which are needed for speedy training of networks.
Initial Review
Dr. Hawley brought a working Python application with him to the Incubator. We analyzed his code to determine how he achieved its functionality and to determine for which libraries we need to find C++ replacements.
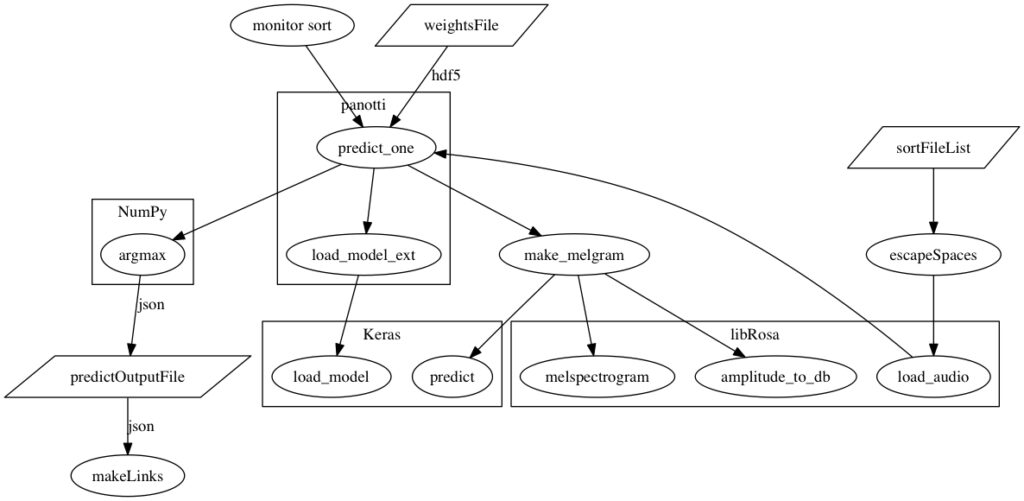
Analysis of Dr. Hawley’s sorting application
His code is dependent on NumPy, a scientific computing library for Python; libRosa, an audio analysis library; and TensorFlow, Google’s neural network library. Actually, Dr. Hawley used Keras (a higher level interface to a few deep learning libraries that simplifies their use) but we can ignore that even though having a similar interface for C++ would make our work easier.
The first task was to identify how to reproduce the functionality in these Python-only libraries.
Step 0
Our app will handle audio to some degree, and we’d like it to run on as many platforms as it can. Our go-to application framework for desktop and mobile audio apps is Juce, but it is also a solid choice for any cross-platform development in C++. JUCE will give us some basic audio features such as reading audio files, playback, and even some processing. There is a lot of other content about JUCE on our blog, and I won’t say more here.
Tensorflow
Of the libraries used in the demo app, Tensorflow is the only one that supports use with C++. However, it doesn’t make its use as simple as I would like. Tensorflow engineers made the assumption that any applications built for it would be developed from within their repository, but that doesn’t work for us. Rather than take a risk by finding some native C++ neural network library–Caffe might be a candidate–we opted to take the pain of the initial Tensorflow setup.
On a previous project, I used tensorflow_cc, which helps linking with tensorflow C++ libraries. This time, I hoped to avoid that and use Tensorflow’s builds directly. I was able to do this, and I will post more about it later.
Others
The rest could be handled with our own code and JUCE. The principal use of libRosa was reading in the audio and analyzing it with a short time Fourier transform (STFT) whose output forms the input to the neural network. The output of the STFT is visualized at the top of this post. JUCE can read the audio files, as I mentioned, and it also provides a Fourier transform (FFT) that we can use to build our own STFT. Using fewer dependencies means the project is easier to manage over time at the cost of some up-front development.
Note About Terms
Note that a synonym for a neural network is a graph, and it is also an easier way to refer to the network. A graph along with weights for the edges of that graph defines a neural network that we can feed our data into one end and get our categories from it at the output end.
Tasks
Now we have our minimal feature set and a good idea about how we can achieve those features. We need to do the following:
- Read audio files (Juce)
- Analyze audio with STFT (my code + Juce)
- Feed the analysis results into our Tensorflow graph
- Read the results from the Tensorflow graph
Next time, with this plan, we get busy creating our project and writing code, and you’ll read about how well this plan did when met with reality.