Introduction
We have a customer that developed a hardware device to make physical measurements. Some years ago we wrote a suite of software tools for the customer: a tablet application for configuring the hardware device, a django web server to receive uploaded XML documents generated by the device, and a user-facing web application (using the same django server), providing reporting and data analytics.
The architecture roughly looks like this (simplified for clarity):
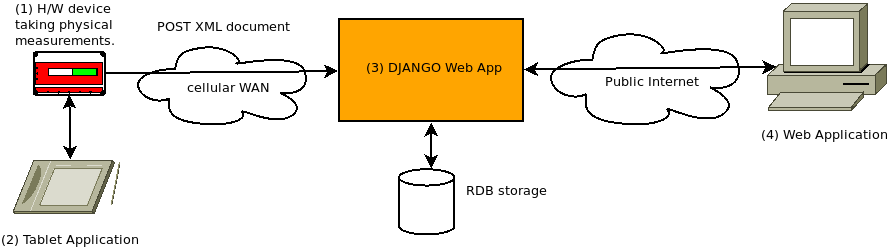
- H/W device: takes data measurements, generates an XML document, and uploads the XML document to the (3) Web App via a cellular WAN.
- Tablet Application: used in the field to configure the device, setting parameters for daily operation and authentication tokens for secure uploads.
- DJANGO Web App: the web app receives the XML documents, parses them, and stores the data in a relational database. It also serves requests from a client-facing web application offering reports and analytics.
- Web Application: a modern browser web application for viewing data and analytics.
The Challenge
After several years of successful operation our customer came back to us with a new requirement: they wanted to use devices with a new mode of communication to ease the burden and costs of using a cellular network, devices based on LoRaWAN.
LoRaWAN, a low-power, wide-area network, presents several challenges:
- It can only transmit 10s to 100s of bytes at a time. This is too small to deliver our 2-3K XML documents, so immediately we know our messages will need to be broken up into several payloads.
- Our solution: if we don’t send XML, but rather the data within the XML as a packed struct, we can shrink the message from several K to approximately 600 bytes, reducing greatly the number of payloads we need to deliver to complete a message.
- When connecting, the device and LoRa gateway will calculate the bandwidth, so each message may be delivered at different data rates and therefore different payload sizes. E.g., message m1 may be delivered in 11-byte payloads, while m2, connecting at a different time, may deliver 242-byte payloads.
- Our solution: if each payload is given a header we can identify which message each payload belongs to. The first payload can include an expected payload count for the complete message. (Metadata delivered by the LoRa gateway identifies the device, so which device is sending the message we get for "free".)
- Payloads may arrive out-of-order.
- Our solution: use the header to identify the payload order, 0, 1, 2, etc. On receiving a complete message (known based on count from payload-0) we can sort the payloads to reassemble the packed struct.
- Individual payloads may be lost.
- Our solution: some data is required, some data is merely metadata not critical to a successful upload. If we’re missing a required payload (particularly payload-0) we log the incident with the message we did received, but otherwise we post the message.
Putting this all together it becomes clear we need a data processing pipeline; something like this:
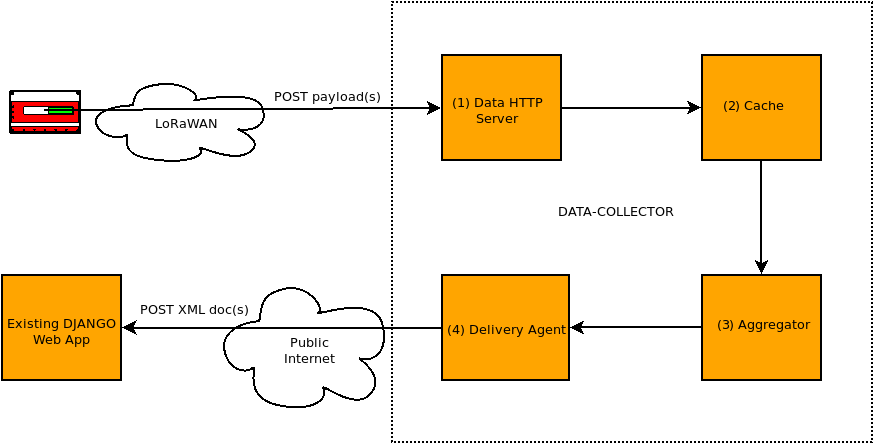
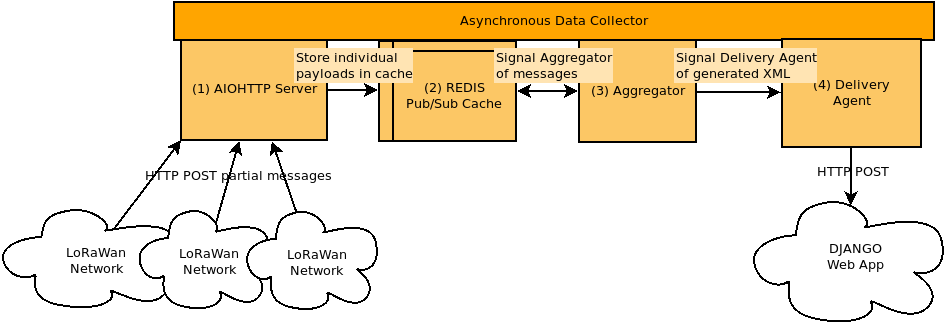
The components of the data-collector:
- An HTTP server accepting POSTs of payloads. After validating a payload, it is stored in (2) cache.
- The cache will store payloads for a message and will pass on the message ID to the (3) aggregator when one of two conditions are met:
- When it has received all payloads, based on having received the expected count of payloads for a message given by payload-0.
- Because payloads may be lost, we may never receive a full message, so the cache is configured with a timeout per message. If a full message is never received the timeout will send the message, as-is, to the aggregator.
- The aggregator will collect all payloads, assemble them in order and, when possible, generate an XML document passing it on to (4) the Delivery Agent.
- The Delivery Agent, on receiving an XML document will manage a connection (and necessary authentication) with the Web App and upload the XML (via a POST call), managing retries and logging on any failure.
Implementing with Asynchronous Python
Modeling a pipeline in asynchronous python is a simple matter of creating tasks and queues. Let’s look at the last two stages of the pipeline, the aggregator and delivery agent as examples.
We will create two queues on application startup and two long-running tasks:
import asyncio
# create queues - for simplicity we ignore sizing the queue here
aggregator_queue = asyncio.Queue()
delivery_queue = asyncio.Queue()
# create tasks - two async functions discussed below
asyncio.create_task(aggregator)
asyncio.create_task(delivery_agent)
The cache can push message IDs onto aggregator_queue whenever a
message completes or times out:
# in cache implementation...
aggregator_queue.put_nowait(message_id)Meanwhile, the aggregator can be implemented structurally like this:
async def aggregator():
"""Aggregator: collect messages and generate XML documents.
"""
while True:
# wait for incoming message
message_id = await aggregator_queue.get()
try:
# fetch payloads and expected count from cache
payloads, count = await cache.get_message(message_id)
# generate full message from payloads
message = generate_message(payloads, count)
# we have a full message: generate XML
xml = generate_xml(message)
# pass on to the next step in the pipeline, a tuple of our
# message ID and generated xml
delivery_queue.put_nowait((message_id, xml))
except Exception as exc:
# we log any error that might have occurred from preceding calls
logger.error('Error processing message id %s: %s', message_id, exc)
finally:
# we tell the queue the task is complete
aggregator_queue.task_done()With a similar structure we can implement the delivery agent:
async def delivery_agent():
"""Delivery agent: listen for incoming XML docs and deliver to Web App
"""
# set up initial connection/authentication here. Let's imagine we
# have a factory function, web_app() that returns our current
# connection to the Web App by way of an [aiohttp
# ClientSession](https://docs.aiohttp.org/en/stable/client_advanced.html#client-session).
# having set up the connection management, we enter our loop:
while True:
# wait for incoming message
message_id, xml = await delivery_queue.get()
try:
# function to generate POST data for REST call
data = gen_post_data(xml)
# get current session from factory and upload
session = web_app()
resp = await session.post(URL, data=data)
# process resp here, handling non 2XX responses, perhaps
# running the above POST in a loop for N-attempts for
# recoverable errors, otherwise raising an appropriate exception.
except Exception as exc:
# we log any error that might have occurred from preceding calls
logger.error('Could not upload xml for message_id %s: %s', message_id, exc)
# perhaps we save the generated XML for review of the failure?
finally:
# we tell the queue the task is complete
delivery_queue.task_done()As we complete our implementation we end up with a software architecture that mirrors our designed pipeline: